
scrapy架构
如图
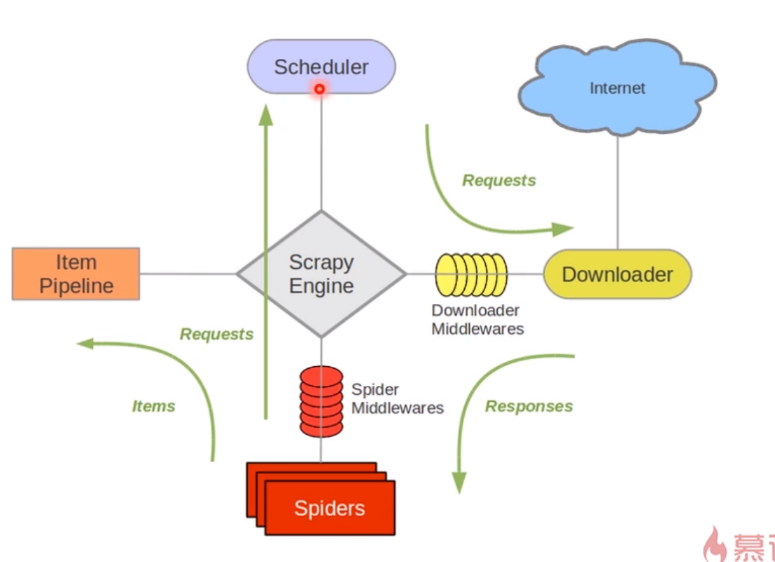
最中间的是scarpy的引擎,引擎指挥Spiders去爬取URL,spiders将requests发往调度器,调度器会针对这些请求进行排队,之后送往dowanloader,downloader会从internet上下载资源,将这些response发往spiders,spiders将其封装好送往item pipeline中
一个spider的工作流程大概就是如上所述
scrapy可以开启一个shell进行调试
1 | (base) C:\Users\zz>scrapy shell https://www.anquanke.com |
此时会得到一些对象
1 | [s] Available Scrapy objects: |
此时可以针对我们的xpath进行调试
xpath如何获得?我们可以自己手动编写,或者直接通过chrome的开发者工具获得
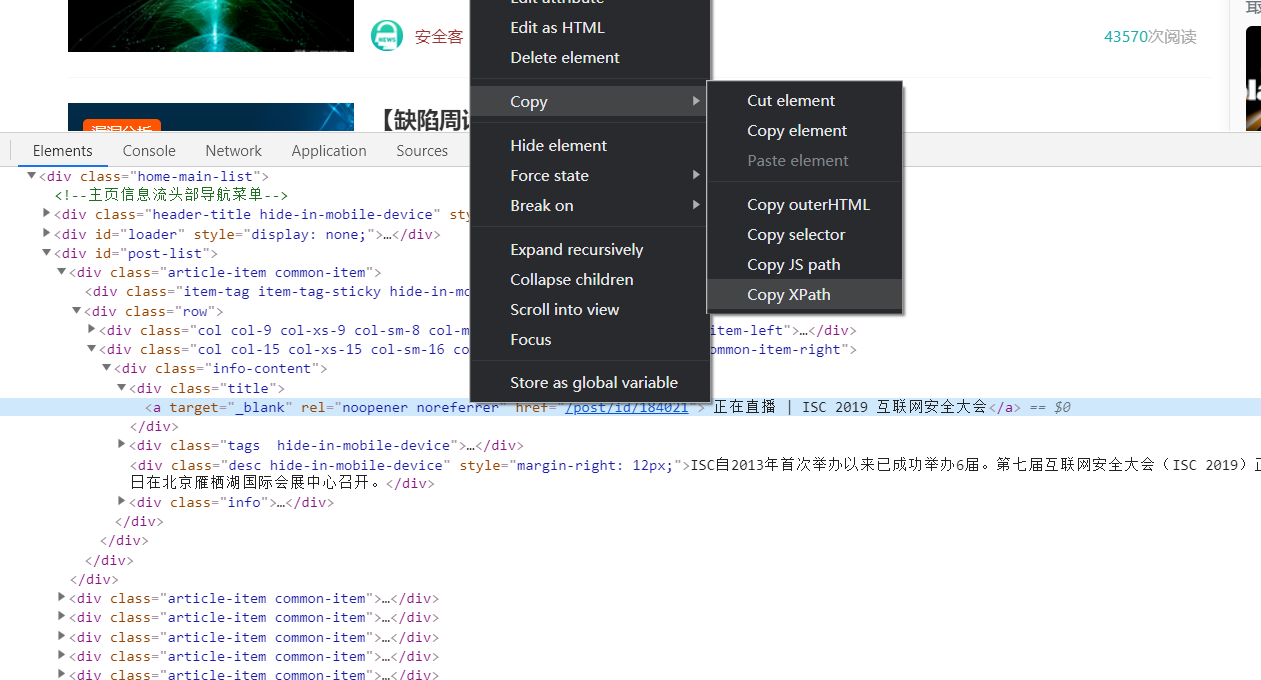
然后尝试一下对不对
1 | In [2]: response.xpath('//*[@id="post-list"]/div[1]/div[2]/div[2]/div/div[1]/a') |
这样就能爬取下来了
一个简单的爬虫
我们看一下官方提供的一个栗子
目录结构如下:
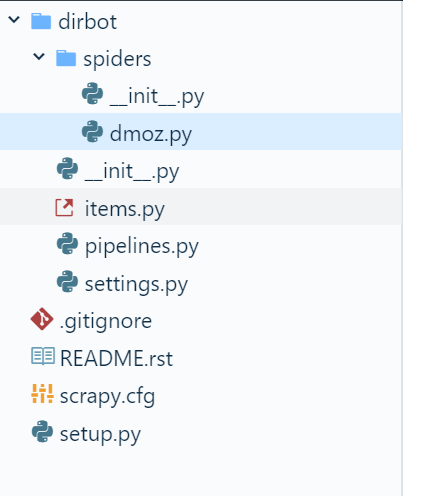
在items.py文件中:
1 | from scrapy.item import Item, Field |
这里定义了我们需要爬取的items,稍后我们将在我们的spider中编写xpath规则来提取我们需要的数据
在dmoz.py中(爬虫的名字叫dmoz,名字必须唯一)
1 | from scrapy.spiders import Spider |
可以看到这就是一个简单的,可以运行的爬虫了
当然还有后续的步骤,包括如何爬取更多的数据,如何换页,如何将数据存入数据库中等等