
似乎好久之前就对这个有疑问了,还是沉下心来好好理解一下
python3中的字符串都是Unicode编码的,我们知道编码是有很多种方式的,最常见的有utf-8,gbk,ascii编码
好我们先来看:
1 | a = 'example' ---> a 是 str类型 |
此时b的值为: b'example'
那这就很奇怪了,明明字母e德utf-8编码是0x65,为什么这里还是原来的??
不妨看这个:
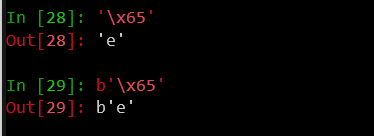
我们看到python默认会将这个解释成对应的字符,那这就很没办法了
但是请看这个:
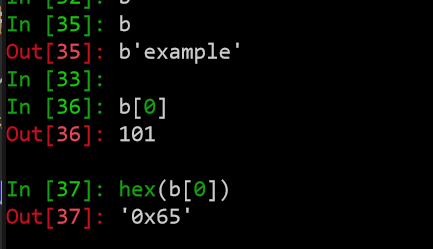
当我们去取出b中的一个元素时,这时候又转成了字母e的utf-8编码,只能说python在这一点上确实做的我无法理解
ok到这里大概疑惑就没了,用什么格式编码得到的byte,就需要用对应的格式解码回去

可以看出不同的编码得到的byte是不一样的,并且python默认会将可打印的字符直接打印出来?
问题
- 十六进制
1 | a = 'example' |
此时res的值为:6578616d706c65
如果要将其变回原来的字符串怎么办
也就是一种ASCII hex编码
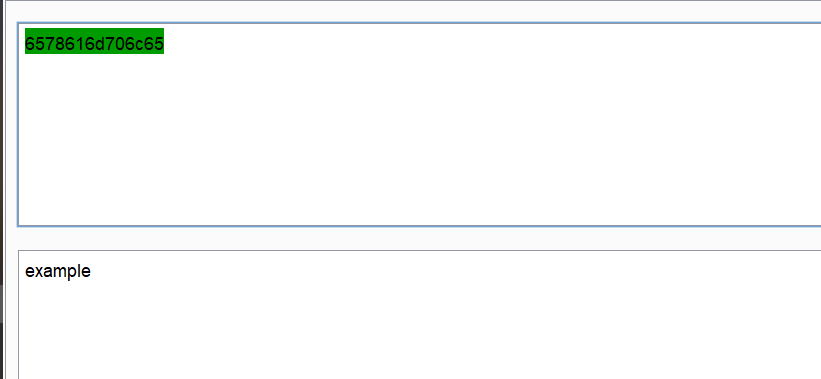
bytes.fromhex(res)这样就行了
