
感知机补充
接着写
感知机的训练中,老师还提供了一部份资料,比如训练出$y=2x$
我们简要地看一下一次训练的结果:
| bias | x | y | w0 | w1 | yout | y-yout | adj0 | adj1 | alpha | w0new | w1new |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.512 | 1.023 | 0.719 | 0.403 | 0.926 | 0.977 | 0.977 | 0.500 | 0.7 | 0.788 | 0.438 |
进行很多次训练之后画出的图形: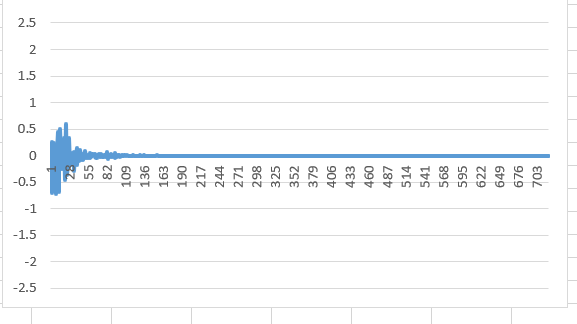
预测的还是挺准确的
为什么需要bias?
概念上很好理解,bias就是将一个正比例函数变为了一次函数,这样不必每次都过原点,分类的准确性也就大大地提高了
多层感知机
一层的感知机是没办法处理异或问题的
所以需要增加隐藏层
就像下面这样: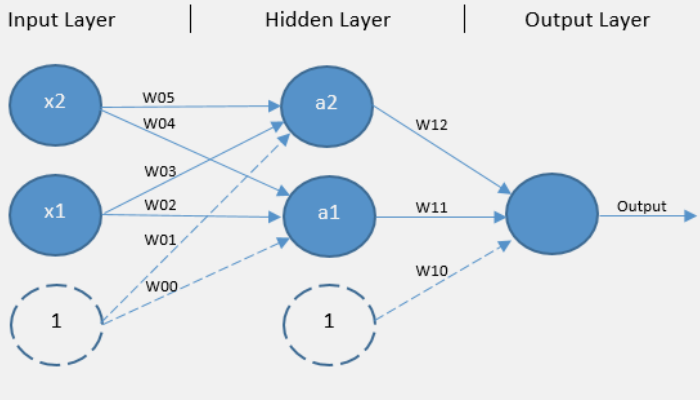
这样就可以做到了:
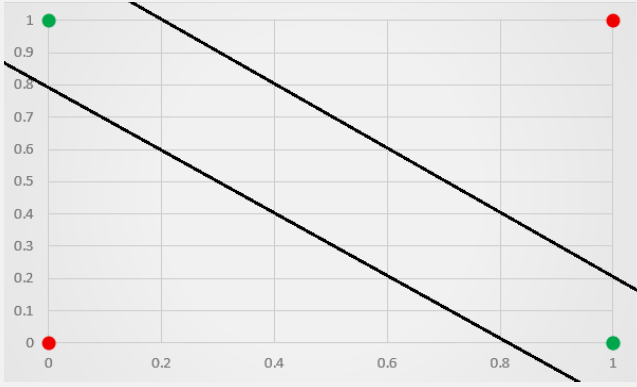
感觉MLP的数学知识太过复杂了,暂时放着
keras
从栗子代码开始:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22from keras.models import Sequential
model = Sequential()
from keras.layers import Dense
'''
使用add来堆叠模型
'''
model.add(Dense(units=64, activation='relu', input_dim=100))
model.add(Dense(units=10, activation='softmax'))
'''
使用compile来配置学习过程
'''
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
# x_train 和 y_train 是 Numpy 数组 -- 就像在 Scikit-Learn API 中一样。
model.fit(x_train, y_train, epochs=5, batch_size=32)
'''
评估模型
'''
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128)
classes = model.predict(x_test, batch_size=128)
Sequential
compile
在训练模型之前,需要配置学习过程,compile接收三个参数
- 优化器optimizer
- 损失函数loss
- 评估标准metrics
一个个来看
优化器
可以先实例化一个优化器对象,然后将它传入model.compile(),或者可以通过损失函数
损失函数(或称目标函数、优化评分函数)是编译模型时所需的两个参数之一:1
model.compile(loss='mean_squared_error', optimizer='sgd')
我们可以传递一个现有的损失函数名,或者一个tensorflow符号函数,有以下两个参数
- y_true: 真实标签.
- y_pred: 预测值,其shape与y_true相同
可用的损失函数:
mean_squared_error
mean_absolute_error
等